Автоматическое масштабирование
Масштабирование — это возможность изменять доступные ресурсы в соответствии с запросами клиентов. Сервисы уровней Scale и Enterprise (со стандартным профилем 1:4) можно масштабировать по горизонтали, программно вызывая API или изменяя настройки в UI для регулирования системных ресурсов. Эти сервисы также могут автоматически масштабироваться по вертикали в соответствии с потребностями приложений.
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Уровни Scale и Enterprise поддерживают как сервисы с одной репликой, так и с несколькими репликами, тогда как уровень Basic поддерживает только сервисы с одной репликой. Сервисы с одной репликой рассчитаны на фиксированный размер и не допускают вертикального или горизонтального масштабирования. Вы можете перейти на уровень Scale или Enterprise, чтобы масштабировать свои сервисы.
Как работает масштабирование в ClickHouse Cloud
В настоящее время ClickHouse Cloud поддерживает вертикальное автомасштабирование и ручное горизонтальное масштабирование для сервисов уровня Scale.
Для сервисов уровня Enterprise масштабирование работает следующим образом:
- Горизонтальное масштабирование: ручное горизонтальное масштабирование будет доступно для всех стандартных и пользовательских профилей на уровне Enterprise.
- Вертикальное масштабирование:
- Стандартные профили (1:4) поддерживают вертикальное автомасштабирование.
- Пользовательские профили (
highMemoryиhighCPU) не поддерживают вертикальное автомасштабирование или ручное вертикальное масштабирование. Однако такие сервисы можно масштабировать вертикально, обратившись в службу поддержки.
Масштабирование в ClickHouse Cloud реализовано с использованием подхода, который мы называем "Make Before Break" (MBB). Сначала добавляются одна или несколько реплик нового размера, и только затем удаляются старые реплики, что предотвращает потерю производительности во время операций масштабирования. Исключая разрыв между удалением существующих реплик и добавлением новых, MBB обеспечивает более плавный и менее нарушающий работу процесс масштабирования. Это особенно полезно в сценариях масштабирования вверх, когда высокая загрузка ресурсов требует дополнительной емкости, поскольку преждевременное удаление реплик лишь усугубило бы дефицит ресурсов. В рамках этого подхода мы ждем до одного часа, чтобы дать существующим запросам завершиться на старых репликах, прежде чем удалять их. Это позволяет сбалансировать необходимость завершения существующих запросов и одновременно гарантировать, что старые реплики не остаются слишком долго.
Вертикальное автомасштабирование
Automatic vertical scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Сервисы тарифов Scale и Enterprise поддерживают автомасштабирование на основе использования CPU и памяти. Мы постоянно отслеживаем исторические данные об использовании сервиса за окно анализа (последние 30 часов), чтобы принимать решения о масштабировании. Если использование выходит выше или опускается ниже определённых пороговых значений, мы масштабируем сервис соответствующим образом, чтобы соответствовать нагрузке.
Для сервисов без MBB-масштабирования автомасштабирование по CPU срабатывает, когда использование CPU превышает верхний порог в диапазоне 50–75% (конкретное значение порога зависит от размера кластера). В этот момент объём CPU, выделенный кластеру, удваивается. Если использование CPU опускается ниже половины верхнего порога (например, до 25% при верхнем пороге 50%), выделение CPU уменьшается вдвое.
Для сервисов, уже использующих подход масштабирования MBB, масштабирование вверх происходит при пороге CPU 75%, а масштабирование вниз — при половине этого порога, то есть 37,5%.
Автомасштабирование по памяти увеличивает кластер до 125% от максимального использования памяти или до 150%, если возникают ошибки OOM (out of memory).
Выбирается большее из рекомендованных значений по CPU или памяти, и CPU и память, выделенные сервису, масштабируются синхронно, с шагом 1 CPU и 4 GiB памяти.
Настройка вертикального автомасштабирования
Масштабирование сервисов ClickHouse Cloud Scale или Enterprise может настраиваться участниками организации с ролью Admin. Чтобы настроить вертикальное автомасштабирование, перейдите на вкладку Settings вашего сервиса и отрегулируйте минимальный и максимальный объём памяти, а также параметры CPU, как показано ниже.
Сервисы с одной репликой нельзя масштабировать для всех уровней.
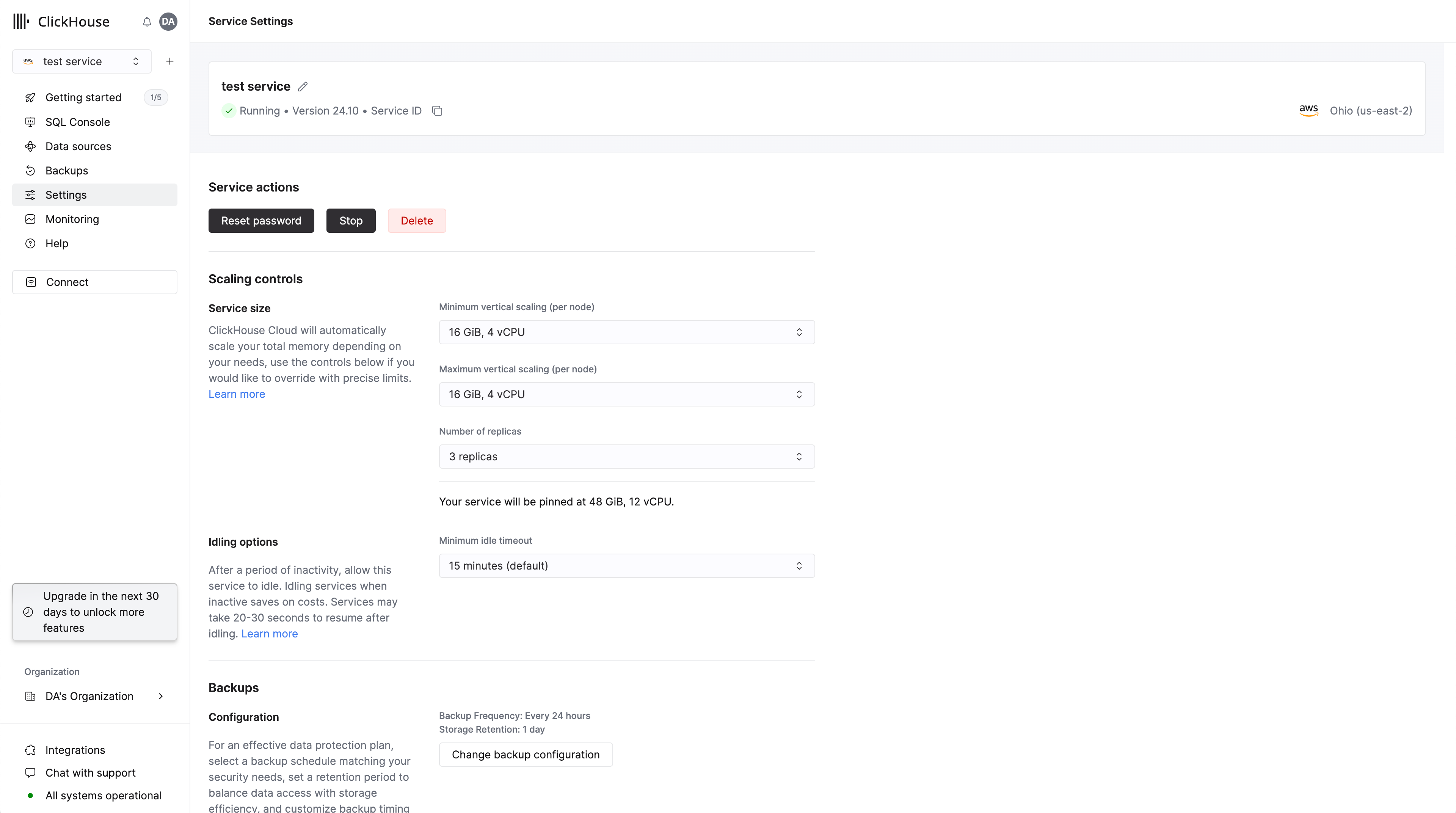
Задайте значение Maximum memory для ваших реплик выше, чем Minimum memory. Сервис будет масштабироваться по мере необходимости в этих пределах. Эти параметры также доступны при первоначальном создании сервиса. Каждой реплике в вашем сервисе будут выделены одинаковые ресурсы памяти и CPU.
Вы также можете установить одинаковые значения, фактически «закрепив» сервис на конкретной конфигурации. В этом случае масштабирование до выбранного вами размера произойдёт немедленно.
Важно отметить, что это отключит любое автомасштабирование в кластере, и ваш сервис не будет защищён от увеличения использования CPU или памяти сверх этих настроек.
Для сервисов уровня Enterprise стандартные профили с соотношением 1:4 поддерживают вертикальное автомасштабирование. Пользовательские профили не поддерживают вертикальное автомасштабирование или ручное вертикальное масштабирование при запуске. Однако такие сервисы можно масштабировать вертикально, обратившись в поддержку.
Ручное горизонтальное масштабирование
Manual horizontal scaling is available in the Scale and Enterprise plans. To upgrade, visit the plans page in the cloud console.
Вы можете использовать публичные API ClickHouse Cloud, чтобы масштабировать сервис, обновляя его настройки масштабирования, или изменять количество реплик через консоль Cloud.
Тарифные планы Scale и Enterprise также поддерживают сервисы с одной репликой. Сервисы, которые были масштабированы по горизонтали, можно масштабировать обратно до минимального значения — одной реплики. Учтите, что сервисы с одной репликой имеют сниженную отказоустойчивость и не рекомендуются для продакшн-среды.
Сервисы могут масштабироваться по горизонтали максимум до 20 реплик. Если вам требуется больше реплик, свяжитесь с нашей службой поддержки.
Горизонтальное масштабирование через API
Чтобы горизонтально масштабировать кластер, выполните PATCH‑запрос через API для изменения количества реплик. На скриншотах ниже показан вызов API для масштабирования кластера с 3 до 6 реплик и соответствующий ответ.
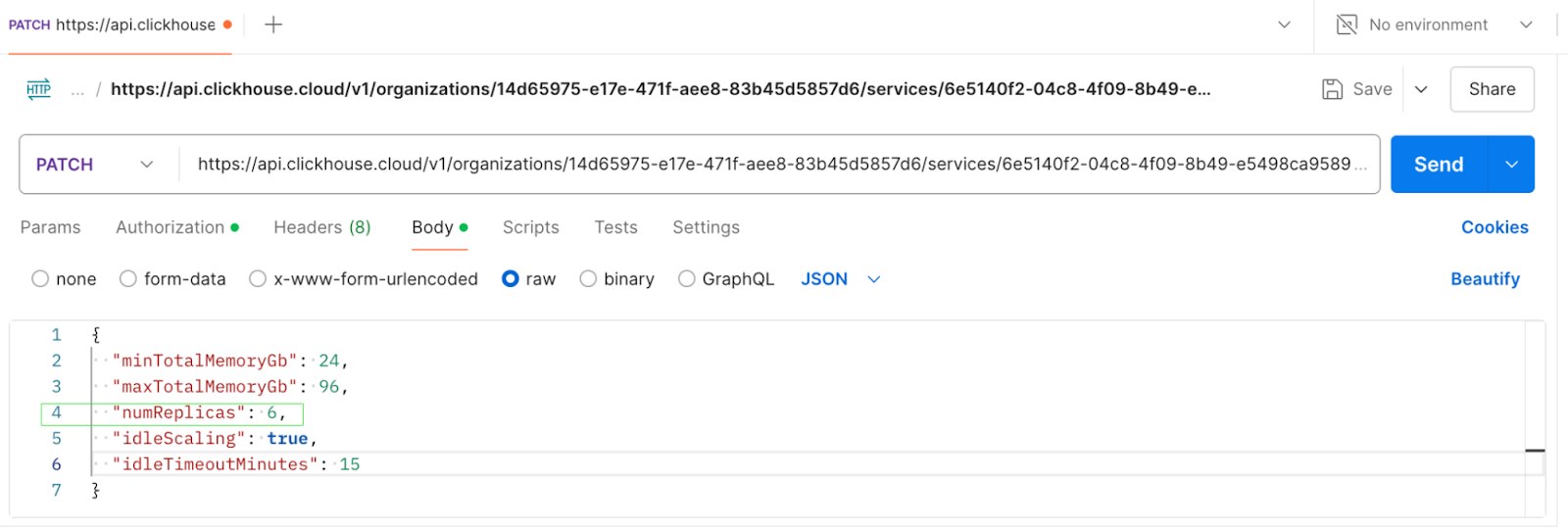
PATCH‑запрос для обновления numReplicas
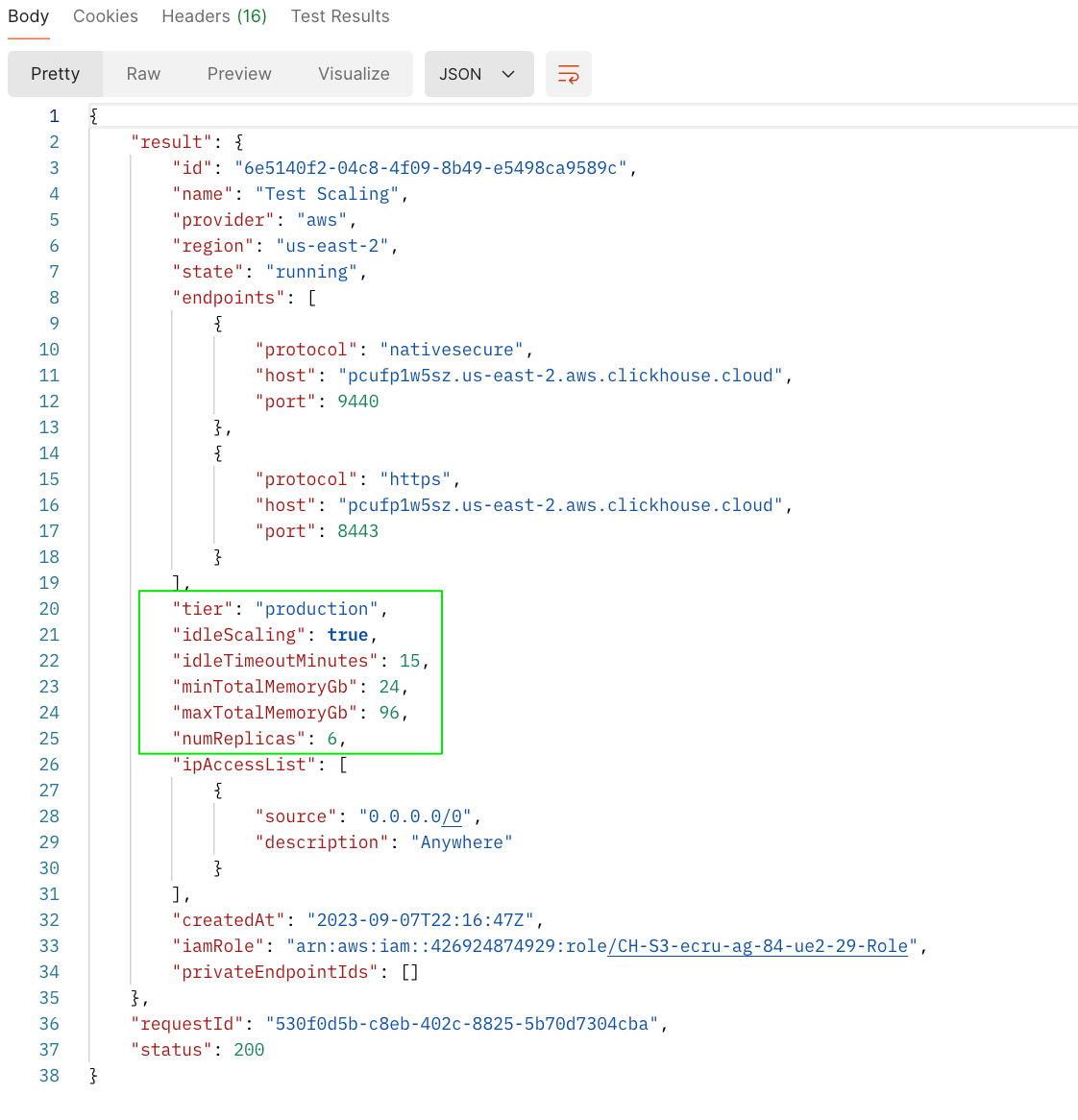
Ответ на PATCH‑запрос
Если вы отправите новый запрос на масштабирование или несколько запросов подряд, пока один уже выполняется, сервис масштабирования будет игнорировать промежуточные состояния и в итоге установит конечное количество реплик.
Горизонтальное масштабирование через интерфейс
Чтобы масштабировать сервис по горизонтали через интерфейс, вы можете изменить количество реплик для сервиса на странице Settings.
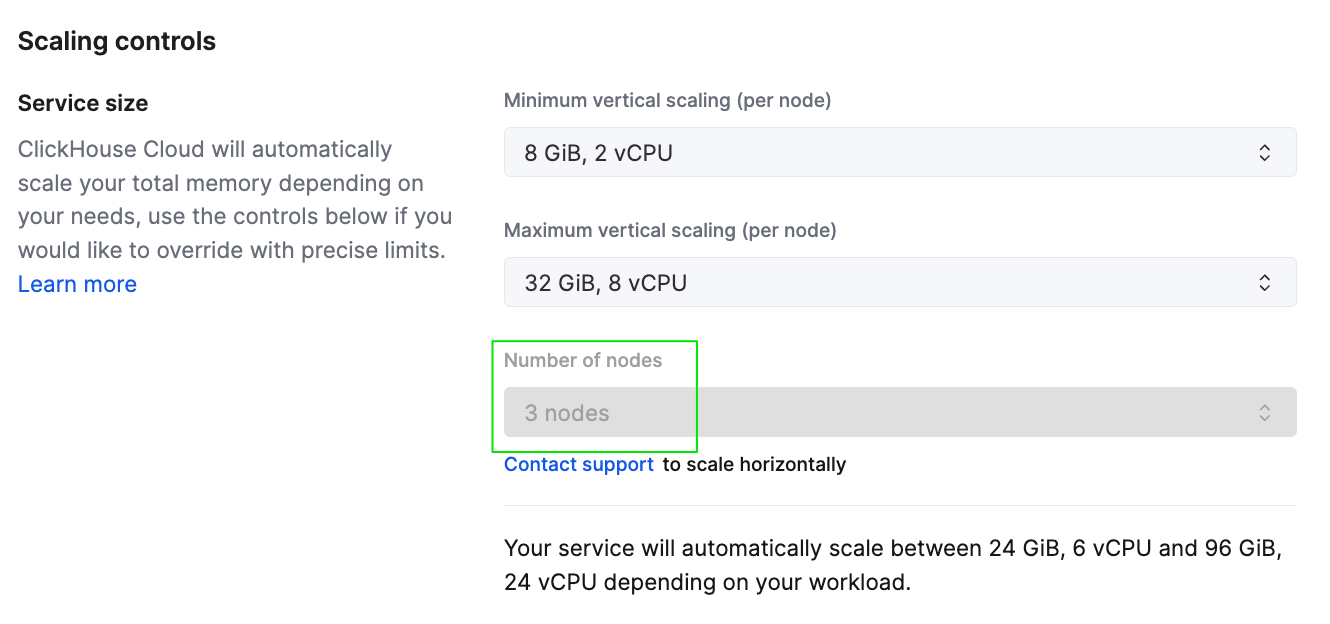
Настройки масштабирования сервиса в консоли ClickHouse Cloud
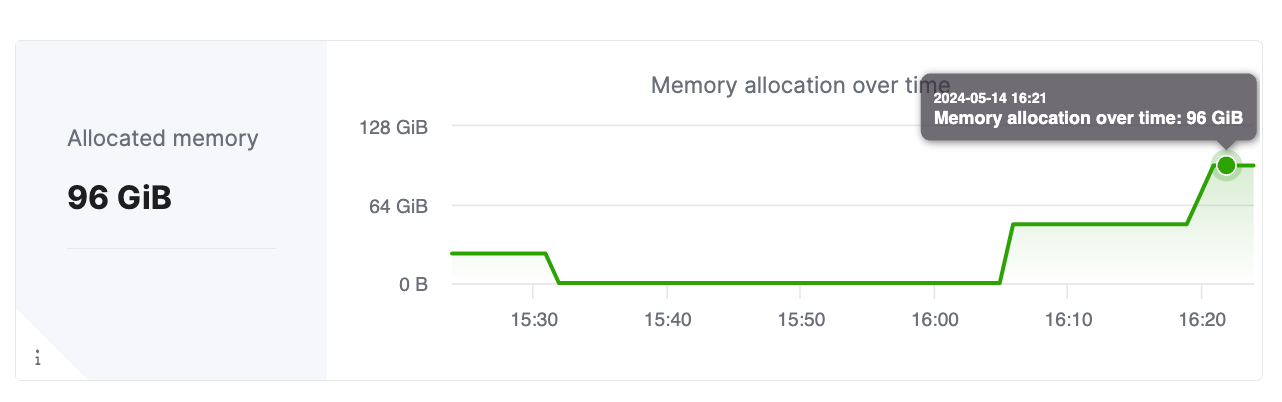
После масштабирования сервиса панель метрик в консоли ClickHouse Cloud должна отразить корректное распределение ресурсов для сервиса. На скриншоте ниже показано, что кластер был масштабирован до общего объёма памяти 96 GiB, что соответствует 6 репликам, каждая из которых имеет по 16 GiB памяти.
Автоматический простой
На странице Settings вы также можете выбрать, разрешать ли автоматический перевод сервиса в режим простоя, когда он неактивен в течение определённого времени (то есть когда сервис не выполняет пользовательские запросы). Автоматический простой снижает стоимость использования вашего сервиса, так как с вас не взимается плата за вычислительные ресурсы, когда сервис приостановлен.
Адаптивный режим простоя
ClickHouse Cloud реализует адаптивный режим простоя, чтобы предотвращать сбои и одновременно оптимизировать затраты. Перед переводом сервиса в простой система оценивает несколько условий. Адаптивный простой переопределяет настройку длительности простоя, когда выполняется любое из перечисленных ниже условий:
- Если количество частей превышает максимальный порог частей для простоя (по умолчанию: 10 000), сервис не переводится в режим простоя, чтобы фоновое обслуживание могло продолжаться
- Если выполняются операции слияния (merge), сервис не переводится в режим простоя, пока эти операции не завершатся, чтобы не прерывать критически важную консолидацию данных
- Кроме того, сервис адаптирует таймауты простоя в зависимости от времени инициализации сервера:
- Если время инициализации сервера менее 15 минут, адаптивный таймаут не применяется, и используется настроенный клиентом таймаут простоя по умолчанию
- Если время инициализации сервера от 15 до 30 минут, таймаут простоя устанавливается в 15 минут
- Если время инициализации сервера от 30 до 60 минут, таймаут простоя устанавливается в 30 минут
- Если время инициализации сервера более 60 минут, таймаут простоя устанавливается в 1 час
Сервис может перейти в состояние простоя, при котором приостанавливаются обновления refreshable materialized views, потребление из S3Queue и планирование новых операций merge. Текущие merge‑операции будут завершены до того, как сервис перейдёт в состояние простоя. Чтобы обеспечить непрерывную работу refreshable materialized views и потребления из S3Queue, отключите функциональность режима простоя.
Используйте автоматический простой только в том случае, если ваш сценарий может выдерживать задержку перед ответом на запросы, поскольку при остановке сервиса подключения к нему будут завершаться по таймауту. Автоматический простой оптимален для сервисов, которые используются нечасто и где задержка приемлема. Он не рекомендуется для сервисов, которые обеспечивают часто используемые, критичные для пользователей функции.
Обработка всплесков нагрузки
Если вы ожидаете предстоящий всплеск нагрузки, вы можете использовать ClickHouse Cloud API, чтобы заранее масштабировать ваш сервис для обработки всплеска и затем уменьшить масштаб, когда спрос снизится.
Чтобы узнать, сколько ядер CPU и памяти в данный момент используется каждой из ваших реплик, вы можете выполнить следующий запрос:
